Step 5: Root cause & iteratively fix quality issues#
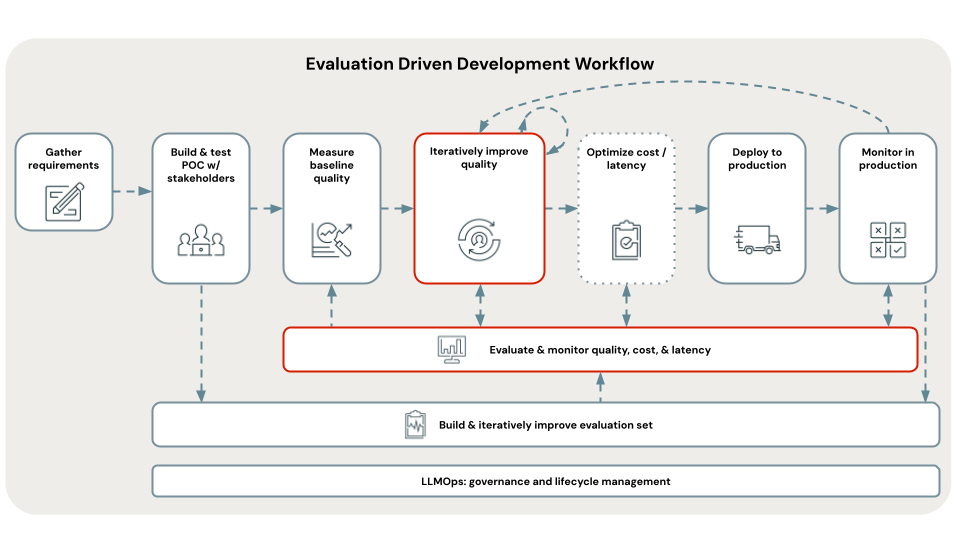
Overview
While a basic RAG chain is relatively straightforward to implement, refining it to consistently produce high-quality outputs is often non-trivial. Identifying the root causes of issues and determining which levers of the solution to pull to improve output quality requires understanding the various components and their interactions.
Simply vectorizing a set of documents, retrieving them via semantic search, and passing the retrieved documents to an LLM is not sufficient to guarantee optimal results. To yield high-quality outputs, you need to consider factors such as (but not limited to) chunking strategy of documents, choice of LLM and model parameters, or whether to include a query understanding step. As a result, ensuring high quality RAG outputs will generally involve iterating over both the data pipeline (e.g., chunking) and the RAG chain itself (e.g., choice of LLM).
You can find all of the sample code referenced throughout this section here.
This step is divided into 2 sub-steps: