1. RAG overview#
This section provides an overview of Retrieval-augmented generation (RAG): what it is, how it works, and key concepts.
1.1. What is retrieval-augmented generation?#
Retrieval-augmented generation (RAG) is a technique that enables a large language model (LLM) to generate enriched responses by augmenting a user’s prompt with supporting data retrieved from an outside information source. By incorporating this retrieved information, RAG enables the LLM to generate more accurate, higher quality responses compared to not augmenting the prompt with additional context.
For example, suppose you are building a question-and-answer chatbot to help employees answer questions about your company’s proprietary documents. A standalone LLM won’t be able to accurately answer questions about the content of these documents if it was not specifically trained on them. The LLM might refuse to answer due to a lack of information or, even worse, it might generate an incorrect response.
RAG addresses this issue by first retrieving relevant information from the company documents based on a user’s query, and then providing the retrieved information to the LLM as additional context. This allows the LLM to generate a more accurate response by drawing from the specific details found in the relevant documents. In essence, RAG enables the LLM to “consult” the retrieved information to formulate its answer.
1.2. Core components of a RAG application#
A RAG application is an example of a compound AI system: it expands on the language capabilities of the model alone by combining it with other tools and procedures.
When using a standalone LLM, a user submits a request, such as a question, to the LLM, and the LLM responds with an answer based solely on its training data.
In its most basic form, the following steps happen in a RAG application:
Retrieval: The user’s request is used to query some outside source of information. This might mean querying a vector store, conducting a keyword search over some text, or querying a SQL database. The goal of the retrieval step is to obtain supporting data that will help the LLM provide a useful response.
Augmentation: The supporting data from the retrieval step is combined with the user’s request, often using a template with additional formatting and instructions to the LLM, to create a prompt.
Generation: The resulting prompt is passed to the LLM, and the LLM generates a response to the user’s request.
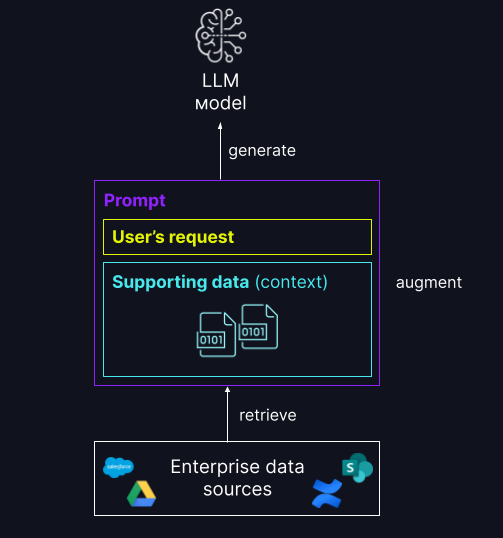
This is a simplified overview of the RAG process, but it’s important to note that implementing a RAG application involves a number of complex tasks. Preprocessing source data to make it suitable for use in RAG, effectively retrieving data, formatting the augmented prompt, and evaluating the generated responses all require careful consideration and effort. These topics will be covered in greater detail in later sections of this guide.
1.3. Why use RAG?#
The following table outlines the benefits of using RAG versus a stand-alone LLM:
With an LLM alone |
Using LLMs with RAG |
|---|---|
No proprietary knowledge: LLMs are generally trained on publicly available data, so they cannot accurately answer questions about a company’s internal or proprietary data. |
RAG applications can incorporate proprietary data: A RAG application can supply proprietary documents such as memos, emails, and design documents to an LLM, enabling it to answer questions about those documents. |
Knowledge isn’t updated in real time: LLMs do not have access to information about events that occurred after they were trained. For example, a standalone LLM cannot tell you anything about stock movements today. |
RAG applications can access real-time data: A RAG application can supply the LLM with timely information from an updated data source, allowing it to provide useful answers about events past its training cutoff date. |
Lack of citations: LLMs cannot cite specific sources of information when responding, leaving the user unable to verify whether the response is factually correct or a hallucination. |
RAG can cite sources: When used as part of a RAG application, an LLM can be asked to cite its sources. |
Lack of data access controls (ACLs): LLMs alone can’t reliably provide different answers to different users based on specific user permissions. |
RAG allows for data security / ACLs: The retrieval step can be designed to find only the information that the user has permission to access, enabling a RAG application to selectively retrieve personal or proprietary information based on the credentials of the individual user. |
1.4. Types of RAG#
The RAG architecture can work with 2 types of supporting data:
Structured data |
Unstructured data |
|
|---|---|---|
Definition |
Tabular data arranged in rows & columns with a specific schema e.g., tables in a database. |
Data without a specific structure or organization, e.g., documents that include text and images or multimedia content such as audio or videos. |
Example data sources |
- Customer records in a BI or Data Warehouse system |
- PDFs |
Which data you use with RAG depends on your use case. The remainder of this guide focuses on RAG for unstructured data.